Evolving Security with machine learning
Petabi REsolutions embraces all data an organization’s information system can produce. This includes traditional log entries and network messages as well as the ability to directly ingest analytic results, anomaly detectors, and any kind of data feed that might contain valuable information as to the state of the organization and its information system. This provides Petabi REsolutions a unique strength in its ability to analyze any system data. It also broadens the detection surface creating more opportunity for correlation which is then exploited to qualify and quantify data. For Petabi REsolutions more data is less! That means the more data we get the better able we are to leverage connections in the data to reduce the data requiring human eyes.
Petabi REsolutions codifies expert knowledge in the form of regular expressions saved into a database. The regular expressions can represent a single instance of a phenomenon in the system (simple events) or can describe relationships between simple events (i.e. complex events). Further, Petabi has created a novel, patented, process for treating all data universally. Thus, the data from any source in the system can be compared to the data from any other source in the system. This makes creating and modifying rules simple and allows the system to easily evolve over time. Machine learning processes run constantly to cluster and organize data as it is ingested and ultimately qualify that data when possible and serve the organized data to a user for feedback when not possible. In fact, Petabi REsolutions can automatically craft signatures to recognize specific phenomenon without any interaction from users. Thus, the system user need only offer judgments backed by extensive reports and summaries. Even better, once a particular phenomenon is quantified and qualified, then it can be detected thereafter without any intervention from system users.
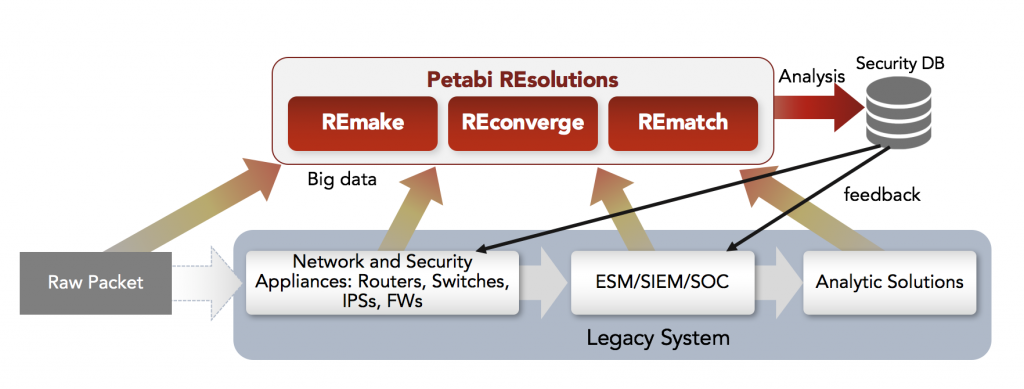
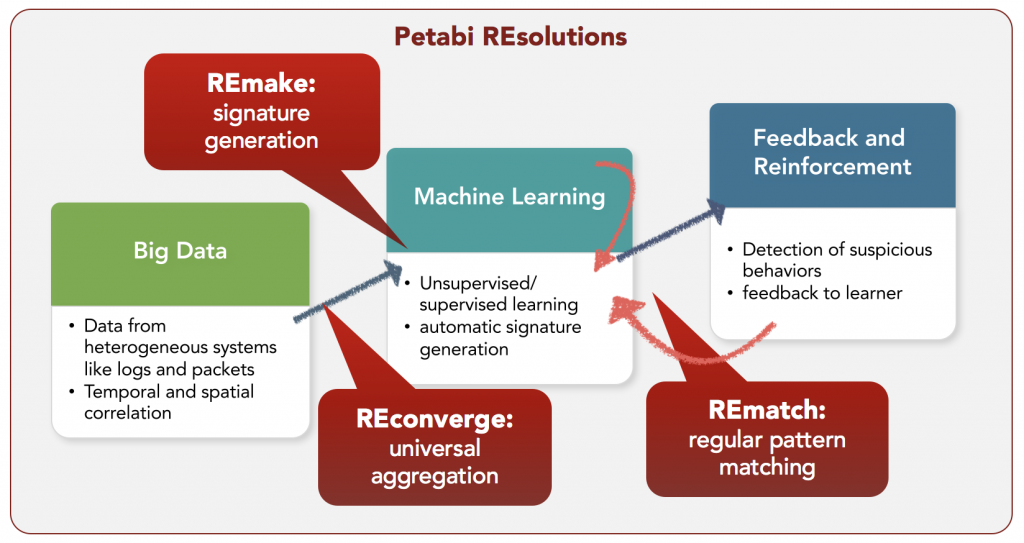
Petabi REsolutions is comprised of three tools: REconverge, REmake, and REmatch as well as a suite of learning and management tools for connecting them together. REconverge provides the means for comparing heterogeneous data in an independent and hierarchical manner of theoretically unlimited size. REmake can produce regular expression signatures given a sample. This sample could be a sampling of packets designated as malicious, a set of spam email, or even a set of particular log events. Finally, REmatch can match thousands of regular expressions against a data stream at line speeds.
Problems facing machine learning
Machine learning is time and resource intensive. This often prevents the use of machine learning techniques as the amount of time to arrive at meaningful results exceeds the time frame at which those results can provide value. As such, any solution must align the learning techniques with the timescale at which those results are to be used. Petabi REsolutions addresses this issue in two ways. First, we recognize that most event analysis occurs at the minute level rather than at the second or subsecond processing levels. The reasoning behind this is that recognizing events at those higher precision time scales is not humanly possible and when done purely autonomously opens the system to potential abuse and churn if the system is updating too frequently. Thus, Petabi REsolutions is designed to operate at scales counted in minutes (though they can operate at higher precision). Time scales of one to two minutes offer precision far superior to human review while providing for optimizing input and batch processing. The second key is that Petabi REsolutions are designed to work in a distributed manner. Thus, the problem can be farmed to multiple processes, potentially on separate hardware, and the results merged by REconverge. Further, the independence of nodes in the system allows the machine learning to work independently without impacting the system. Finally, training can occur offline. Thus, most of the resources required for learning are mitigated by the scale of use and partitioning of event streams to separate, independent, processes with results adopted as soon as they become available. Thus, learning occurs at the chosen time scale with great reliability.
Effective, dynamic, and heterogeneous learning
The prime competitive advantage for Petabi REsolutions is the power of REconverge to ingest any kind of data and treat it equally. This ‘Universal Format’ provides a lingua franca for events such that any event can be modeled as a language, and further, as a regular expression. REconverge can create a detector out of any data stream. It provides the means to codify expert knowledge as regular expressions indicating particular behaviors as well as the means to compare and correlate events across data streams also using regular expressions. This wide flexibility grants REconverge the ability to work with any data stream. Machine learning is a tool and is less about superiority of the tools so much as applying the correct tool for the correct job. REsolutions flexibility allows the seamless adoption of the correct tool for the job rather than try and force every problem to fit the one tool a solution might have. In fact the dynamism of REsolutions lends itself to adding more means of detection and monitoring more streams of data rather than relying only on a few. Thus, REsolutions can adopt any learning technique that can demonstrate value to the system. Further, REsolutions offers both the ability to codify events as rules and match them deterministically as well as the ability to employ anomaly detection directly. Finally, REconverge is an abstraction of the actual data which means that REsolutions can process data separately from actual data collection. Thus, the data can be collected and analyzed separately, or at the same time, dependent on the desires of the system stakeholders. The byproduct of this flexibility is demonstrated in the following strengths.
1. Hybrid: REsolutions is both a rule-based system employing rules as well as a learning system employing various learning techniques to learn the system. As such, it gains the ability to detect events at high rates of speed with high precision, ease of update, as well as the ability to adapt to the environment and evolve over time.
2. Scalable: A node in the REsolutions system is independent and modular, but can also become part of a larger system. REsolutions nodes can link together like building blocks to create a large hierarchical system that can apply multiple layers of learning and aggregation to simplify event processing.
3. Dynamic: The use of regular expressions to codify identified inter-event behaviors allows REsolutions to easily add new behaviors and update behaviors. It also provides operators a wide syntax with which to translate expertise into codified system behaviors which can greatly simplify the update and maintenance of the system. Finally, the use of high-speed regular expression matching means that this dynamism comes at no cost in run-time performance.
4. Layered: REsolutions embraces the idea of processing events in multiple layers. Each layer can provide a means to aggregate, correlate, or simplify the data as well as learn behaviors from the data. Further, each layer operates independently only taking the input from a lower layer and providing an output to a higher layer.
5. Unified: The primary goal of REsolutions is to provide a unified system for an organization. This unification includes the ingestion of all events relevant to the organization as well as the mining of correlations from that data. REsolutions provides a one-stop shop for understanding the state of the system at any time.